
A few years ago I was made engineering lead for the AI team at Irembo. The goal sounded simple on paper: build agentic AI capabilities into Rwanda’s public service platform.
Here’s what “simple” actually meant. Irembo is where 12 million people go to get almost anything they need from their government. A birth certificate for a newborn. A marriage certificate for an upcoming wedding. A death certificate for a lost loved one. And another 200 or 300 services in between.
Now add the hard part. Mobile phones are nearly everywhere here, penetration sits around 87%. Smartphones are another story: only about a third of households own one, and mobile internet use is lower still. Put that next to real gaps in literacy and digital confidence, and you get a country that’s connected on paper but cautious in practice. When something has “government” attached to it, people take it seriously, and seriously means carefully. Plenty of folks won’t risk getting it wrong on a website by themselves.
So Rwanda did something smart. It built a network of ground operators, Irembo agents, spread into every corner of the country. If you’ve got a smartphone but not the nerve to face a government portal alone, you walk to an agent and they get you the service you came for.
How the Irembo agent network brings public services to every corner of Rwanda.
— Irembo (@TeamIrembo) June 26, 2026
That’s the world our AI assistant had to live in. The job was to earn the trust of an entire population, in Kinyarwanda, on the documents that define a person’s legal life.
I’d spent years getting good at shipping software. This project ignored most of that. Here are the 6 lessons it taught me instead.
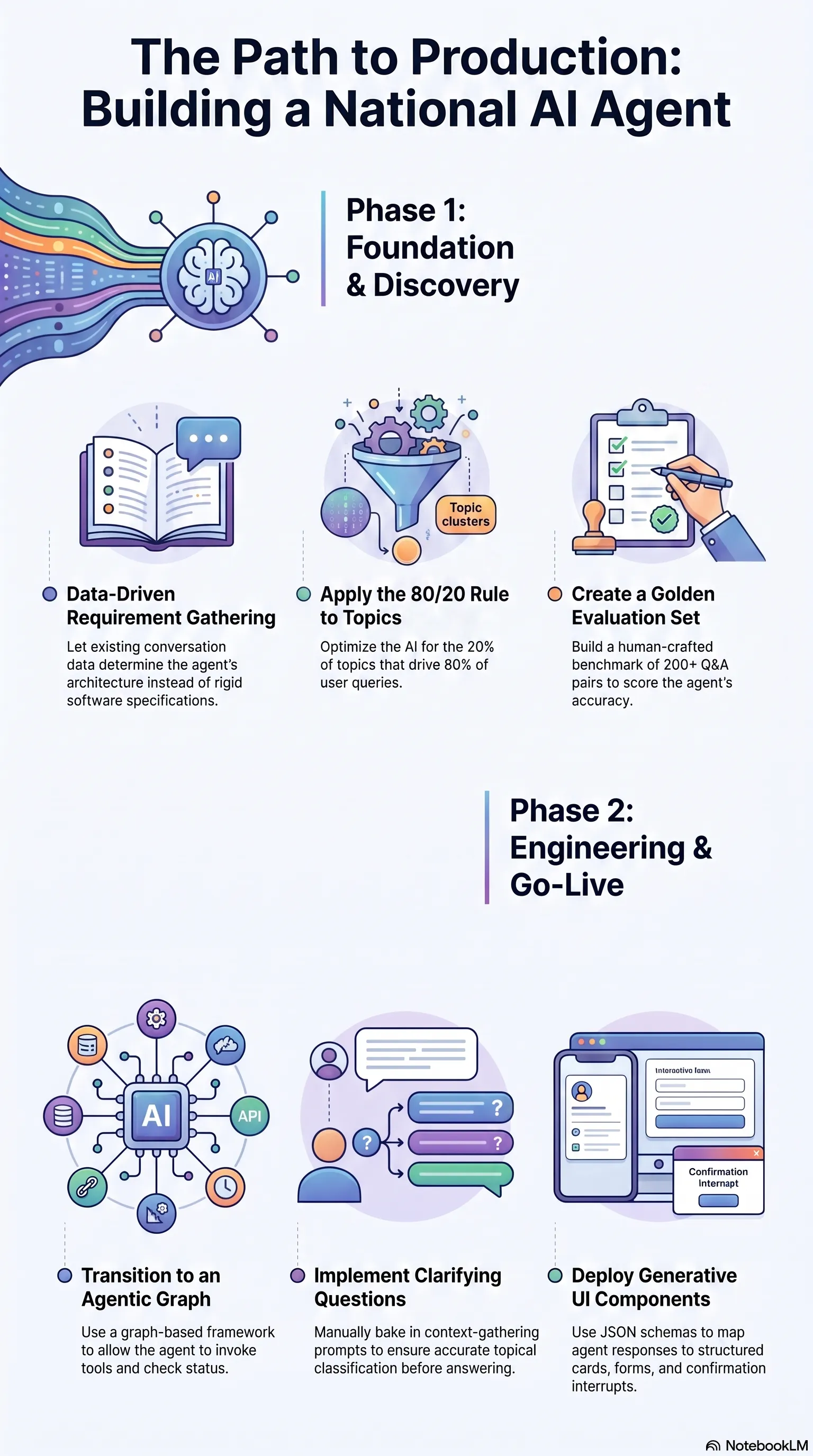
The whole journey on one page. Foundation first, then engineering and go-live.
1. Your AI doesn’t need to know everything
We hit a wall early, and it was a wall we’d built ourselves. We were over-engineering the assistant’s knowledge base, trying to make it fluent across every government service Irembo offers.
Then I sat down with our Head of Customer Experience, and the pattern fell out of the data fast. 80% of help desk queries land on the same 20% of topics. Health insurance in season. The status of an application someone already submitted. How to get a marriage certificate. The same handful, over and over.
Chasing perfection across the long tail of obscure services is a fool’s errand. So we flipped the priority: be at least as good as a human on the top 20% of topics, and make peace with being weaker on the rare stuff.
It made sense that our AI assistant should optimize for that 20% of topics and be extremely good at that and be at least at human level at answering those.
2. The data is the specification
In normal software you start with a PRD, a product requirements doc. Someone tells you what to build, you go build it.
In AI engineering, if a person hands you a 50-page requirements doc up front, they’re guessing (or they’re lying). Nobody actually knows how the agent should behave until they watch it handle real data.
So you don’t write the requirements. You dig them out. Past conversations, decision logs, policy documents, the trail an expert leaves behind. Somewhere in that digging it clicked. We were cloning the brain of a subject matter expert, modelling how they think, the reasoning underneath the steps.
Which leads to a hard truth for any lead:
A problem with AI starts as a problem with data. If you don’t have the data to model how your SME reasons, your agent stays a toy.
No prompt rescues you from that.
3. “Useful” beats “hallucination-free”
The whole industry is chasing zero hallucinations. For a national service, I’d argue usefulness is the better target.
Picture a citizen asking about a service Irembo doesn’t even offer. A strictly “hallucination-free” bot says “I don’t have that information.” Technically accurate. Completely useless to the person standing there waiting.
We built for the next step instead. If we can’t solve it, hand back a template answer or point the person to the rightful public authority. If we can’t help you ourselves, we tell you exactly who can.
The goal here isn’t to be hallucination-free… the goal is to be useful to the human. And so that’s where the AI part of the AI engineering comes in because it’s more than just the technical side. It’s also the governance and ethical side.
4. From RAG Fusion to agentic graphs
Our technical path was a string of breakthroughs that each started life as a failure.
We began with a plain RAG stack, LangChain and Postgres. To push accuracy up, we tried RAG Fusion: let the LLM rewrite a user’s question into 3 variations to widen the blast radius of what we retrieved. We also stopped staring at BLEU and ROUGE scores (those measure translation quality, not intelligence) and put document relevance at the centre of how we judged ourselves.
Then came the real crisis: the translation loop. Early on we’d take a Kinyarwanda question, translate it to English, retrieve the answer, and translate it back. It fell apart on 2 fronts. The latency was brutal, and the Kinyarwanda that came out the other end sounded terrible to native speakers. Our CX team wouldn’t sanction it for a live environment, and they were right.
The fix was moving to LangGraph, and it was non-negotiable. We needed a framework that treated the assistant as a structured graph of nodes rather than a mash-up of functions.
That bought us 4 things. First-class memory, so context retention was native instead of clunky session glue. Specialised nodes, so the “brain” split cleanly into classification, retrieval, and tool calls. An LLM-as-a-judge layer that audited responses against our benchmarks whenever accuracy dipped. And clarifying-question nodes, because LLMs are far too eager to answer. Sometimes the smartest move is to stop and ask “did you mean X or Y?” before doing anything at all.
5. Markdown is a bad interface for government
We learned quickly that a wall of text is a poor way to deliver a public service. If someone needs to pay a traffic fine, what they want is a button. Right there. One tap.
So we went with what I call static generative AI.
The intelligence is generative, but the interface is deterministic.
The agent emits a strong JSON schema, and that schema maps to pre-baked React components we already trust.
Spot a certificate request, trigger the specific form component built for it. Spot a payment, render the payment card. And the piece I care about most, interrupts: for any high-stakes action, the agent hits a node that halts everything until the person manually confirms. The agent never gets to invent a financial transaction or file a legal application on someone’s behalf. A human says yes first, every single time.
6. From process to personality
The final shift was the deepest.
Cloning the steps an expert follows gets you a competent agent. Cloning how they actually sound gets you one people trust.
So we wrote a Voice Bible, a profile that pinned down the assistant’s tone, its fillers, its Kinyarwanda vocabulary, the whole texture of how it should speak. And to keep ourselves honest, we benchmarked every change against a Golden Set of 200 human-crafted questions.
What this all adds up to
So where does this leave us as AI leads? I’ve come to think about the work differently. We’re building digital clones of our best subject matter experts, and that’s a different craft from shipping software.
Whoever maps the nuance of human expertise into a machine most faithfully wins this. The size of the model matters far less than people like to think.
The job is quietly turning from writing code into modelling minds. And honestly, I’m here for it.